
Здравствуйте друзья, коллеги.
В очередной раз решил с Вами поделиться рецептом исправления ошибки в движке BlogEngine.NET
Проблема
Настроив свой блог и начав создавать новые посты, я столкнулся на первый взгляд с непонятным "багом". Иногда в некоторых постах начали пропадать русские буквы в некоторых словах, а вместо них иногда появляться последовательности символов типа: ��.
Решение
В процессе дебага был обнаружен следующий код:
/// <summary>
/// The web resource filter.
/// </summary>
public class WebResourceFilter : Stream
{
#region Constants and Fields
/// <summary>
/// The _sink.
/// </summary>
private readonly Stream sink;
string HtmlOut;
...
/// <summary>
/// Initializes a new instance of the <see cref="WebResourceFilter"/> class.
/// </summary>
/// <param name="sink">
/// The sink stream.
/// </param>
public WebResourceFilter(Stream sink)
{
this.sink = sink;
HtmlOut = "";
}
...
/// <summary>
/// When overridden in a derived class, writes a sequence of bytes to the current stream and advances the current position within this stream by the number of bytes written.
/// </summary>
...
public override void Write(byte[] buffer, int offset, int count)
{
// collect all HTML in local variable
var html = Encoding.UTF8.GetString(buffer, offset, count);
HtmlOut += html;
}
...
/// <summary>
/// Write stream to the client before closing.
/// </summary>
...
public override void Close()
{
...
// parse custom fields
HtmlOut = CustomFieldsParser.GetPageHtml(HtmlOut);
var outdata = Encoding.UTF8.GetBytes(HtmlOut);
sink.Write(outdata, 0, outdata.GetLength(0));
sink.Close();
}
...
}
Было установлено, что метод void Write(byte[] buffer, int offset, int count) неоднократно вызывается в процессе одного реквеста и и мало того, если пост большой, то и несколько раз на на один пост. В сумме с тем фактом, что в метод приходит массив байт, которые являются частью UTF-8 строки с символами выходящими за пределы ASCII и имеющими размер более одно байта (для локализованных блогов) - это и приводит к проявлению описанных артефактов.
Остановимся на этом месте подробнее.
UTF-8
Основная статья: UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт
Из этого следует, что все английские буквы, цифры, специальны символы в UTF-8 будут закодированы как и в ASCII и их размер будет 1 байт. Все остальные символы будут закодированы последовательностями с размером от 2-ух байт.
Пример. Буква "А" из Кириллицы будет закодирована двумя байтами HEX: 04 и 10:
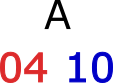
Рис 1
Соответственно в контексте вышеупомянутого, может возникнуть ситуация, когда в метод void Write(byte[] buffer, int offset, int count) поступит массив байт UTF-8 последовательностей полученных при кодировании символов. Последними элементами этого массива могут быть первые байты последовательности символа с размером последовательности два и более байт. То есть в массиве будут не все, а только первые байты последовательности последнего символа.
Соответственно в выражение var html = Encoding.UTF8.GetString(buffer, offset, count); метод Encoding.UTF8.GetString не сможет правильно раскодировать буфер последовательностей символов. Скорей всего его последние байты будут представлять совсем другой символ или вообще никакого (в случае управляющих или не имеющих ассоциации с символом байт последовательности). Это касается и первых байты в буфере при следующем вызове void Write(byte[] buffer, int offset, int count), которые будут представлять оставшиеся байты последовательности последнего символа из предыдущего вызова. Подобное поведение скорей всего приведёт к появлению упомянутых артефактов.
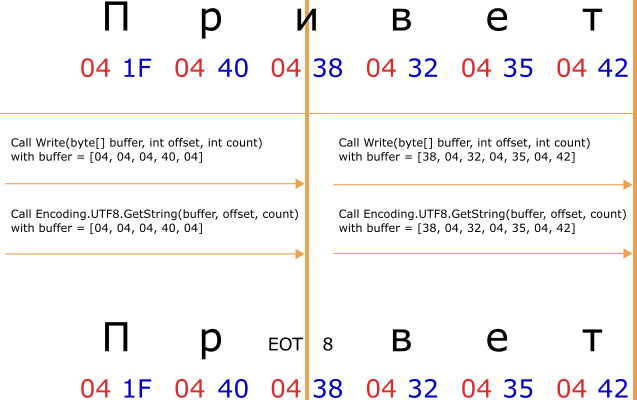
Рис 2
Как видно из рисунка, после первого вызова
void Write(byte[] buffer, int offset, int count) в HtmlOut будет указатель на строку: "Прих[EOT]", а после второго вызова в HtmlOut будет указатель на строку: "При[EOT]8ет", что после некоторых фильтраций и будет записано в Response. В результате эта строка вместе с остальным HTML уйдёт клиенту и скорей всего будет показано как: "При8ет", HEX код 04 (EOT) при рендеринге будет пропущен, так как является не печатаемым, а управляющим кодом.Надеюсь всё понятно.
Решение
Не долго думая, было решено переписать код так, что бы куски строк не декодировались по мере поступления, а их байты накапливались в неком буфере уровня объекта. И уже непосредственно при необходимости использования строки целиком - декодировались. Это позволило бы раскодировать строку полностью без возникновения артефактов. Так как последовательности всех символов строки, целиком находились бы в этом буфере.
Собственно вот то что получилось:
/// <summary>
/// The web resource filter.
/// </summary>
public class WebResourceFilter : Stream
{
#region Constants and Fields
/// <summary>
/// The _sink.
/// </summary>
private readonly Stream sink;
private IList<byte> htmlOutBytes = new List<byte>();
...
public WebResourceFilter(Stream sink)
{
this.sink = sink;
htmlOutBytes = new List<byte>();
}
...
public override void Close()
{
var htmlOutBytesArray = htmlOutBytes.ToArray();
var htmlOut = Encoding.UTF8.GetString(htmlOutBytesArray, Zero, htmlOutBytesArray.Length);
...
}
...
/// <summary>
/// When overridden in a derived class, writes a sequence of bytes to the current stream and advances the current position within this stream by the number of bytes written.
/// </summary>
...
public override void Write(byte[] buffer, int offset, int count)
{
// collect all HTML in local variable
htmlOutBytes.AddRange(buffer.Skip(offset).TakeWhile((item, index) => index < count).ToArray());
}
...
}
Ссылки
Спасибо за внимание.
Хорошей Вам жизни и до новых встреч.